 综合讨论
综合讨论 有问有答
有问有答 供需合作
供需合作
有时候我们通过spy工具下载的LP上面有后门,轻则我们的流量被跳转到别人的LP上,重则整个服务器中马。
正确处理spy来的LP是每个media buyer的必备技能。处理LP需要一点点前端常识,不懂技术只要按照我的步骤来就行,非常简单。如果你是技术大佬,请忽略这篇……
开始之前先说一下怎么快速下载网页。有些人在用一些奇怪的在线工具下载网页,但是下回来的页面经常变得非常奇怪:有些功能失效了,有些地方无故多了许多字。
其实chrome有很多下载网页的插件,只要在chrome store里搜一下“网页下载”即可。比如这个:
梦想网页资源下载器 – Chrome 应用商店 (google.com)
当页面被下载回来,就需要开始处理网页了,就两步,很简单。
检查所有文件
首先用浏览器打开下回来的html文件,按f12,看看有没有报错。
比如我刚刚下载回来的LP:
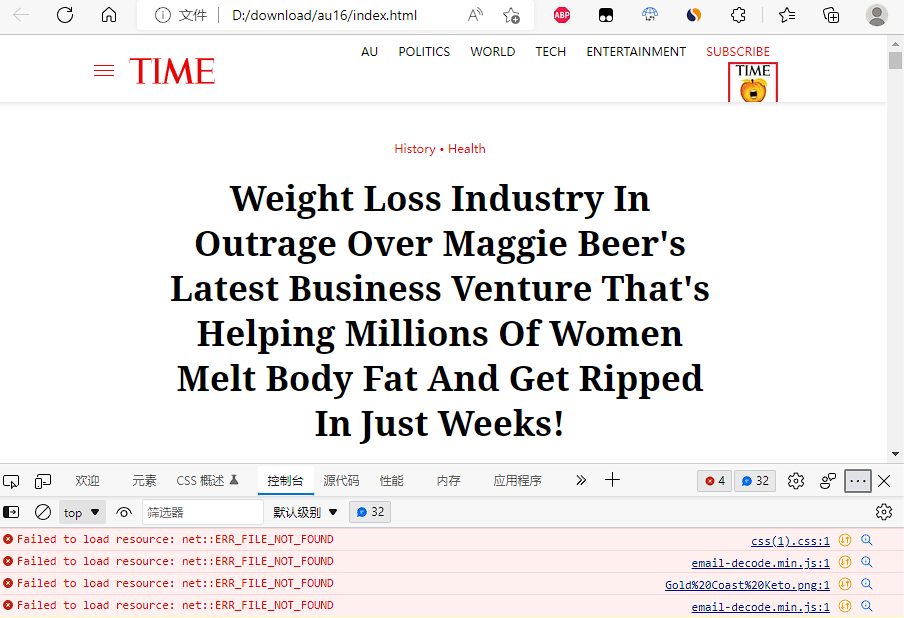
有4个错误,说文件找不到。其中css结尾的是样式文件,如果整个网页看上去没啥问题的话就不用管,在源码里艘关键字然后给他删了。
还有两个JS,那个应该是cloudflare加密邮箱用的,也不用管,也在源码里给删了。
最后有个PNG也没找到,检查一下页面源代码,发现源码是
<img alt="" src="Gold Coast Keto.png">
而下载回来的文件是这样的:
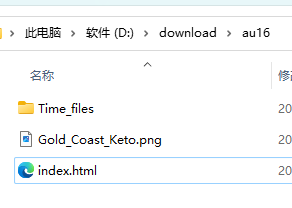
因为有些下载器不能下载带空格的文件,所以这个问价被重命名了,那我们把它改成
Gold Coast Keto.png
再刷新一下,这次产品图显示出来了,其他错误页没了。
检查script代码
接下来要仔细检查所有JS。首先看看下载回来的那些文件里有没有JS文件。
如果有的话记住文件名,在这里搜一下
cdnjs – The #1 free and open source CDN built to make life easier for developers
如果能搜到就直接删了,然后再html源码里找到相应为那一行,给他替换成CDN里的文件。注意要对应一下版本,要不可能会出现奇怪的问题。
我看过太多把后门藏到本地jquery的文件了,而CDN上面的一般不会有问题。
之后要检查一下写在html源码里的脚本,搜 <script,看看每一段代码都是干嘛用的。最常见的应该是这样
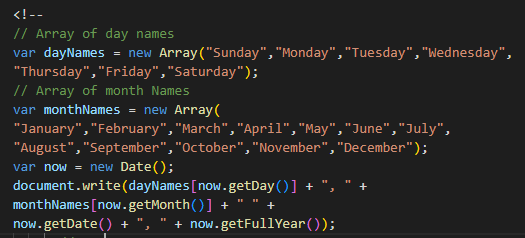
这种是调用时间的,没什么危害,可以留下。
如果遇到自己不明白的js,最好找个懂的人帮忙看看,看是否有危害。如果实在不认识人,就把整段js删了,再用浏览器打开网页,看看有没有什么错误。没影响的js全都可以删掉。
以上全部完成,一个LP就基本处理干净,只要把产品名和offer链接换成自己就可以使用了。


还有挺多点要注意的,有些LP会把图片放到css里面,也得改动挺多的。其次就是一些不知道功能的JS脚本
代码还是要懂的,不然蒙蔽的~